spark集群和开发环境搭建 |
您所在的位置:网站首页 › idea spark开发环境 › spark集群和开发环境搭建 |
spark集群和开发环境搭建
|
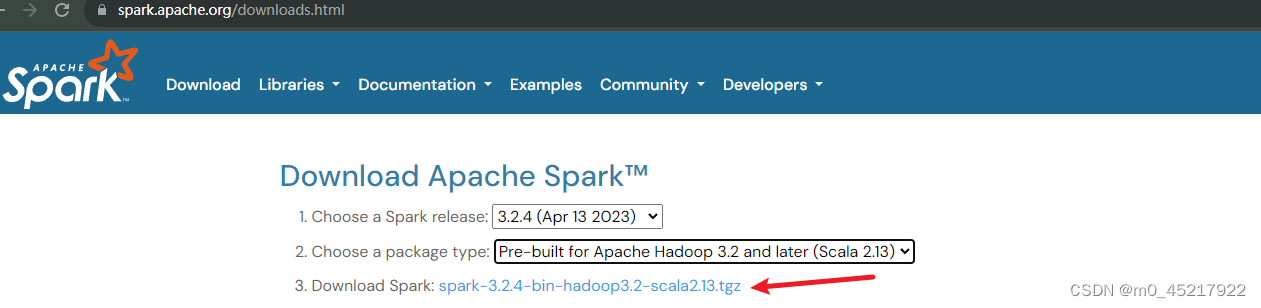
背景:hadoop100,hadoop101,hadoop102三台服务器上已经安装了hadoop集群 一:集群搭建 1.1 安装包下载地址:Downloads | Apache Spark
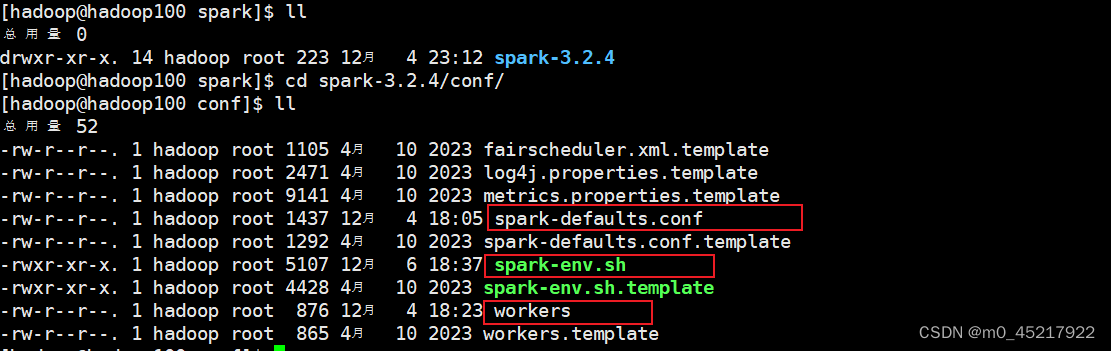
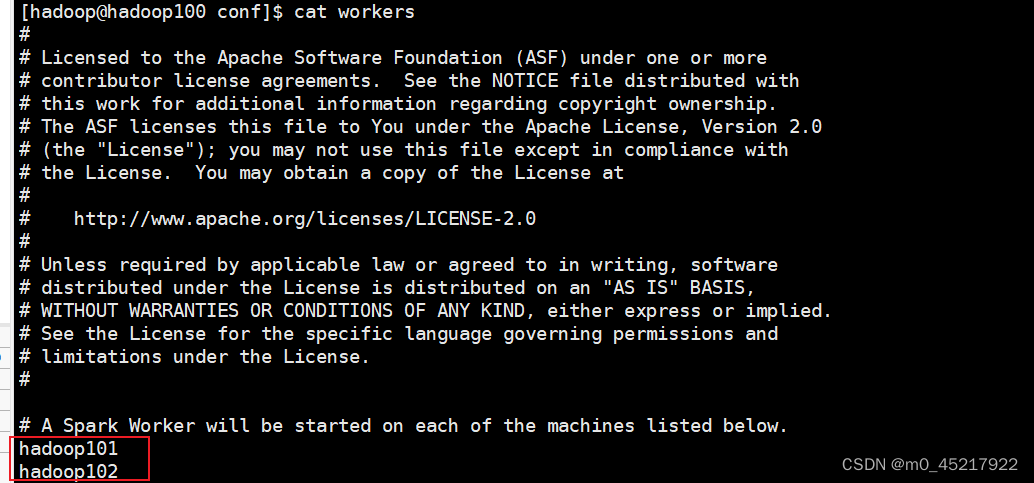
添加下列内容到文件末尾 spark.master spark://hadoop100:7077 spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 1g spark.executor.memory 1g 1.3.3 修改vim spark-env.sh添加下列内容到文件末尾 export JAVA_HOME=/opt/java/jdk8 export HADOOP_HOME=/opt/hadoop/hadoop-3.2.2 export HADOOP_CONF_DIR=/opt/hadoop/hadoop-3.2.2/etc/hadoop export SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop-3.2.2/bin/hadoop classpath) export SPARK_MASTER_HOST=hadoop100 export SPARK_MASTER_PORT=7077 1.3.4 修改vim workers
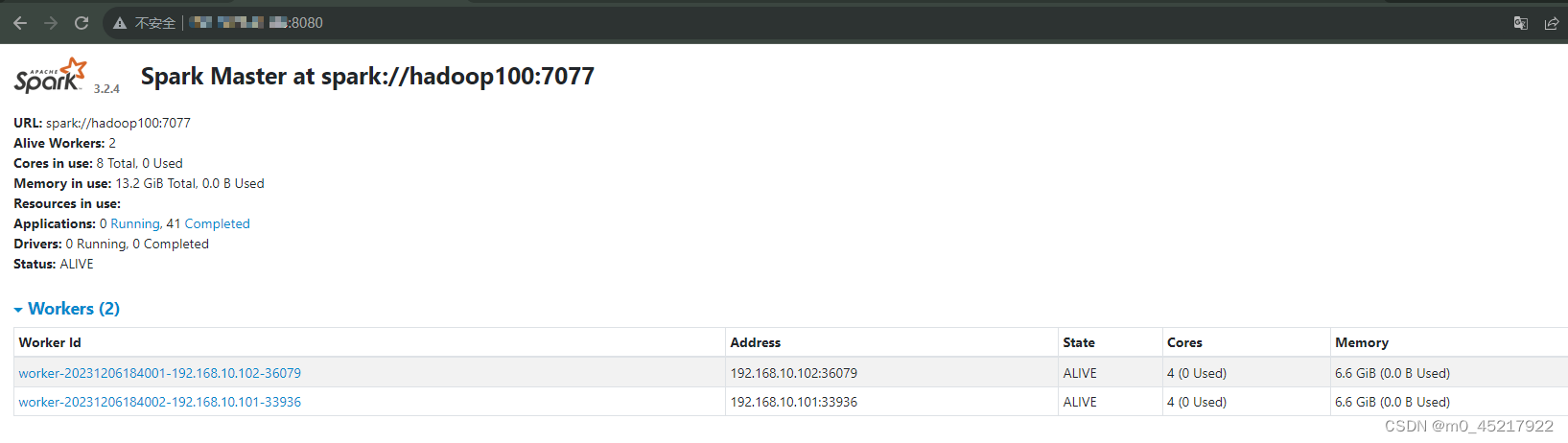
export SPARK_HOME=/opt/spark/spark-3.2.4 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin 1.4 文件分发和启动 1.4.1 文件分发scp -rf /opt/spark hadoop@hadoop101:/opt scp -rf /opt/spark hadoop@hadoop102:/opt 同时在hadoop101和102上添加环境变量 1.4.2 启动服务器 先启动hadoop集群 然后到spark的sbin目录下 ./start-all.sh 通过jps查看是否启动成功 成功标志:hadoop100出现Master hadoop101,hadoop102出现Worker 通过浏览器查看:输入hadoop100:8080
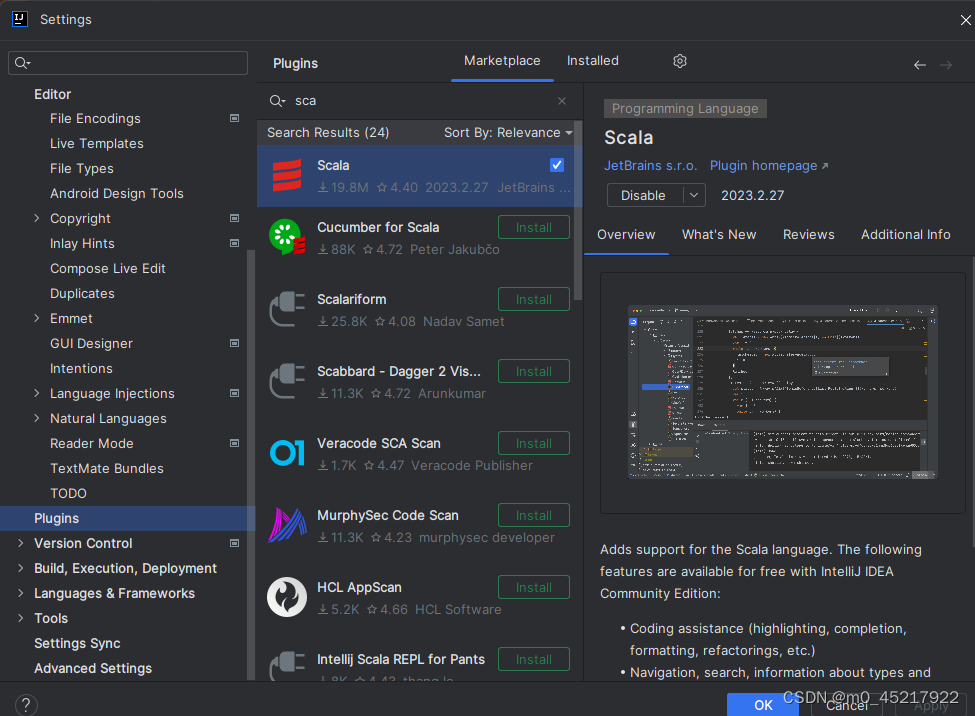
然后到spark的bin目录下 spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi /opt/spark/spark-3.2.4/examples/jars/spark-examples_2.13-3.2.4.jar 出现下列类似信息(该图来源网络) 下列图片为后续的开发环境设置导致无法在服务器上启动,只能监听 到此spark集群的搭建就完成了。 二:idea开发调试环境的搭建 2.1 idea基础环境的准备 2.1.1 scala插件的安装file>settings>plugins>marketplace:搜scala然后安装
官网地址:All Available Versions | The Scala Programming Language
下载和spark的scala版本一致或者小于的版本;这里我下载的是2.13.5的 然后解压下载的压缩包放到合适的位置 2.1.3 创建maven项目porn.xml配置 4.0.0 test SparkPi 1.0-SNAPSHOT 3.2.4 2.13 nexus-aliyun Nexus aliyun http://maven.aliyun.com/nexus/content/groups/public org.apache.spark spark-core_${scala.version} ${spark.version} org.apache.spark spark-streaming_${scala.version} ${spark.version} org.apache.spark spark-sql_${scala.version} ${spark.version} org.apache.spark spark-hive_${scala.version} ${spark.version} org.apache.spark spark-mllib_${scala.version} ${spark.version} junit junit 3.8.1 compile org.scala-tools maven-scala-plugin 2.13.1 compile testCompile maven-compiler-plugin 3.6.0 1.8 1.8 org.apache.maven.plugins maven-surefire-plugin 2.19 true创建scala目录,标记为Sources Root
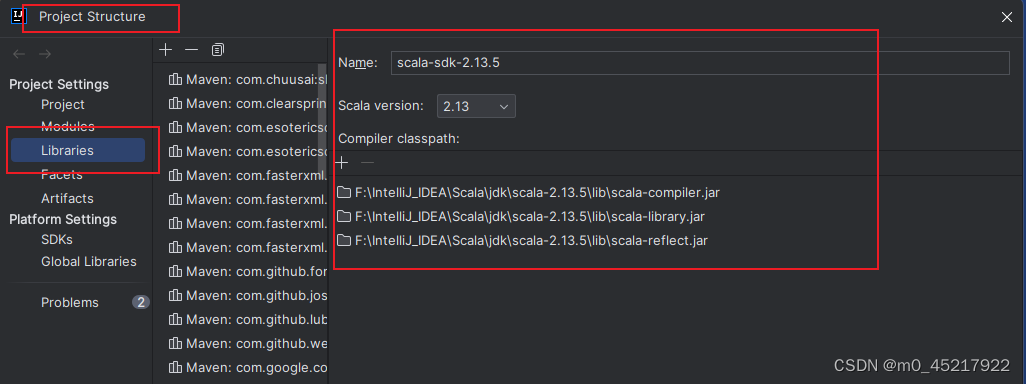
file>Project Structure>Libra > 添加scsla目录 ,就是之前解压的目录
到此基础环境搭建完成,接下来就是连接spark集群 2.2 idea连接spark集群 2.2.1 集群配置文件更改将下列代码添加到spark-env.sh 末尾(集群上所有机器都要) export SPARK_SUBMIT_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005" # address:JVM在5005端口上监听请求,这个设定为一个不冲突的端口即可。 # server:y表示启动的JVM是被调试者,n表示启动的JVM是调试器。 # suspend:y表示启动的JVM会暂停等待,直到调试器连接上才继续执行,n则JVM不会暂停等待。2.2.2 配置idea remote
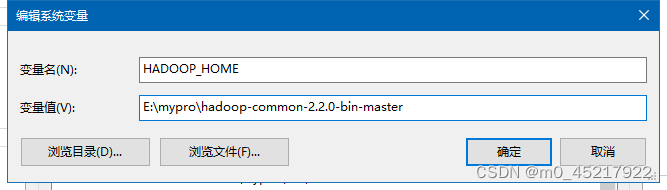
2.2.3 window配hadoop环境 下载地址:https://github.com/steveloughran/winutils 这里用了hadoop3.0.0 配置环境变量
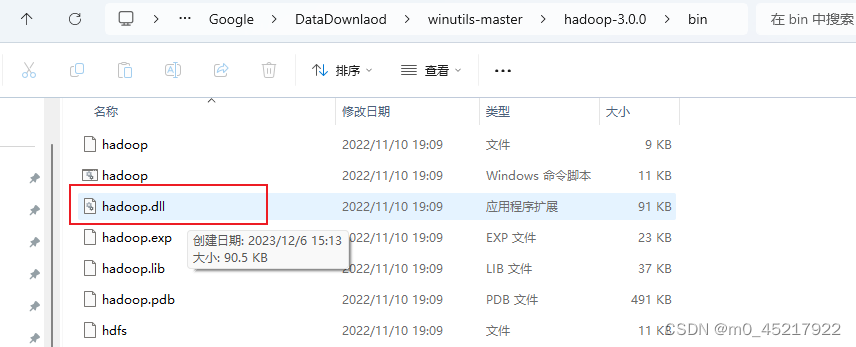
配置ddl
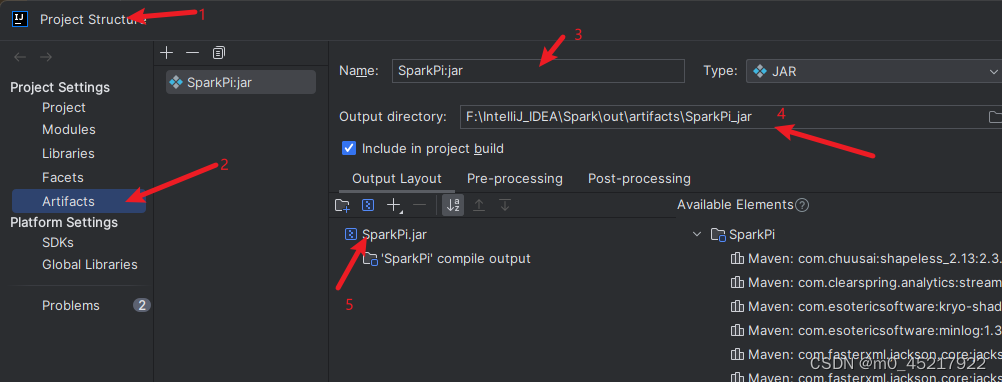
将该文件复制到C:\Windows\System32 目录下 2.2.4 代码调试这里需要一定的scala基础 在scala目录下创建Test 配置jar
测试代码:如果windows没有配置映射ip,就直接输入ip import scala.math.{log, random} import org.apache.spark._ import org.apache.spark.sql.Row.empty.schema import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types.{StructField, StructType} import org.sparkproject.dmg.pmml.False object Test { def main(args: Array[String]): Unit ={ val conf = new SparkConf().setAppName("Test").setMaster("spark://hadoop100:7077") .setJars(Seq("F:\\IntelliJ_IDEA\\Spark\\out\\artifacts\\SparkPi_jar\\SparkPi.jar")) .set("spark.driver.host","localhost") val sc: SparkContext = new SparkContext(conf) val data_0=sc.textFile("hdfs://hadoop100:9000/spark/user.txt") val dataGroupBy4=data_0.map(line=>{ val word=line.split(" ") (word(4),1) }).reduceByKey(_+_) println("按点击来源聚合:") dataGroupBy4.collect().foreach(println) println("==================") val dataGroupBy34=data_0.map(line=>{ val word=line.split(" ") ((word(3),word(4)),1) }).reduceByKey(_+_) println("按设备和点击来源聚合:") dataGroupBy34.collect().foreach(println) println("==================") sc.stop() } }user.txt内容: 1 1001 2023-07-20 12:00:00 手机 首页 2 1002 2023-07-20 13:00:00 电脑 搜索 3 1003 2023-07-20 14:00:00 平板 商品详情 4 1004 2023-07-21 12:00:00 手机 首页 5 1005 2023-07-21 13:00:00 电脑 搜索 6 1006 2023-07-21 14:00:00 平板 商品详情 7 1007 2023-07-22 12:00:00 手机 首页 8 1008 2023-07-22 13:00:00 电脑 搜索 9 1009 2023-07-22 14:00:00 平板 商品详情 10 1010 2023-07-23 12:00:00 手机 首页 11 1011 2023-07-23 13:00:00 电脑 搜索 12 1012 2023-07-23 14:00:00 平板 商品详情 13 1013 2023-07-24 12:00:00 手机 首页 14 1014 2023-07-24 13:00:00 电脑 搜索 15 1015 2023-07-24 14:00:00 平板 商品详情 16 1016 2023-07-25 12:00:00 手机 首页 17 1017 2023-07-25 13:00:00 电脑 搜索 18 1018 2023-07-25 14:00:00 平板 商品详情 19 1019 2023-07-26 12:00:00 手机 首页 20 1020 2023-07-26 13:00:00 电脑 搜索 输出结果:
到处开发调试环境搭建完毕。 参考资料:idea配置 spark集群搭建 windows下hadoop配置 |




【本文地址】
今日新闻 |
推荐新闻 |